Pig && Hive 简介
pig和hive简单来说是使用类sql的语言来做mapreduce jobs数据查询与处理的框架。对于比较复杂的MR程序,可以直接使用缝钻噶后的Pig Latin或者HQL来做,由框架将其转化为hadoop jobs。pig属于大规模数据处理系统,而hive则属于hadoop的一个数据仓库应用。
Pig
虽然被淘汰了,但还是要简单了解一下pig,毕竟是曾经风靡一时的框架。先简单看一下pig的代码:
1 | users = load 'users.csv' as (username: chararray, age: int); |
Pig 好处:
使用pig latin的好处有:
- pig latin懒加载,可以在pipeline中存储任意节点,而sql无法存储中间结果(可以说pig latin是将sql分拆成单个子语句)。
- 使用pig latin而不是直接写hadoop jobs可以极大的减少代码量,减轻程序员负担。
- pig latin的运行效率不会太慢,同一个job所用时间不超过原生MR jobs的两倍。
语言特性:
- Keywords:Load, Filter, Foreach, Group By等,与sql相似
- Aggregations:Count, Avg, Sum,Max等,这些操作一般来说会shuffle job
- Schema:在load数据的时候就需要声明schema
- User Defined Functions(UDFs):用户定义的函数,需要先定义在jar包里,然后在pig latin里用register注册对应jar包从而进行调用
Pig 简单架构如图:
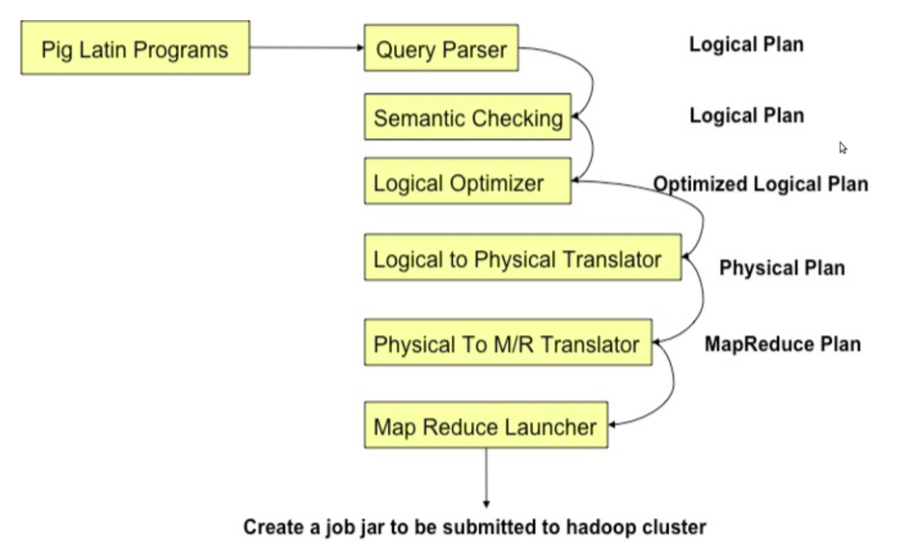
注意:基于效率原因,pig后面使用Tez取代直接做mapreduce jobs。
Tez
Hadoop2.x对hadoop的架构进行了大规模的改动,其中比较重要的是:
- 使用Yarn进行资源管理
- 将Tez作为Pig和hive的执行引擎(而不是直接用mapreduce)
- 提供了各种各样的用户api,支持更多应用
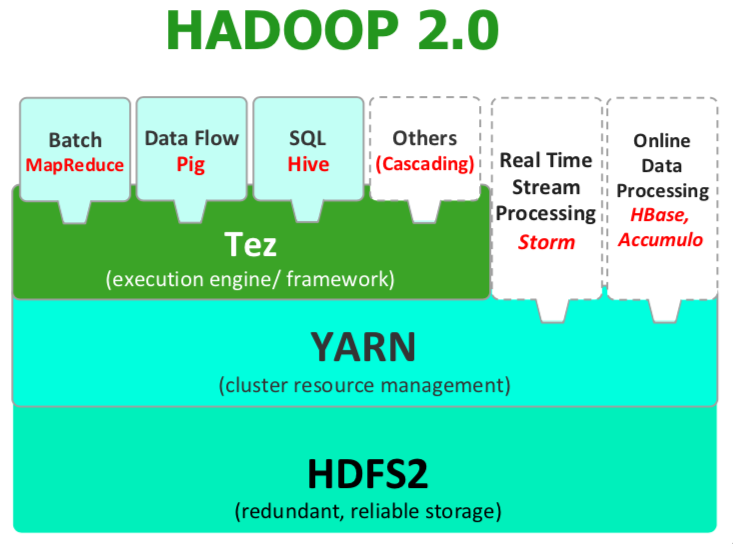
Tez执行步骤:
Tez是一个基于DAG的框架,具体运行pig步骤为:
- 将pig的数据处理过程表示成一个DAG图
- Tez本身可以用来执行基于DAG的计算过程,在此过程中可以优化mapreduce的流程,提高效率。
Hive
hive是一个基于hadoop的数据仓库组件,提供了总结,查询和分析等功能。实际使用时,Hive很像SQL database,HQL的命令也和SQL很像。
Hive安装与启动
- 从apache官方下载hive
- 在conf/下新建hive-site.xml,配置mysql,hdfs等相关设置
- 修改conf/hive-env.sh,配置HADOOP_HOME和HIVE_CONF_DIR
- hive直接进入cli,hiveserver2 & 可以开启hive server
Hive数据模型
hive处理的是结构化的数据,有三个层次:
- Tables(path/warehouse/t)
- 每列都有类型(int,string,boolean)
- 与关系型数据库的table很像
- 每个表对应了hdfs的一个文件目录
- 支持list、map,类似json的数据
- Partitions (path/warehouse/t/2)
- 由数据在表里的分布决定(例如基于范围的partition)
- 每个partition在表的目录下都有自己的子目录
- Buckets (path/warehouse/t/2/part-00000.part)
- partition可以进一步被分成buckets
- 每个bucket被存在目录下的一个文件里
HiveQL命令
HQL的命令主要有三类
- Data Definition Language(DDL):例如create,table,drop table等
- Data Manipulation Language(DML):load和insert命令等
- Query Statements:select,join,union等
Create:
1 | Create table student( |
在使用create时要声明:
- schema:(类似RDBMS)
- partitions:partitioned by(province string)来确定partitions的名字,其中partition的列名不能是schema中已有的
- bucket:则通过clustered/sorted by (id)来实现,其中的列名必须是schema中已有的,还要明确分成几个bucket
- format:指原数据的分隔符是什么,如果表声明为’\t’,而text文件用空格分开,则load的数据皆为null
- stored:存储形式,推荐用orc
Load:
1 | Load data local inpath 'path of local file system' overwrite into table student partition(province='shanxi') -- 加载本地text文件 |
对于有partition的表,在load数据时一定要声明partition,否则会报错
Hive整体架构
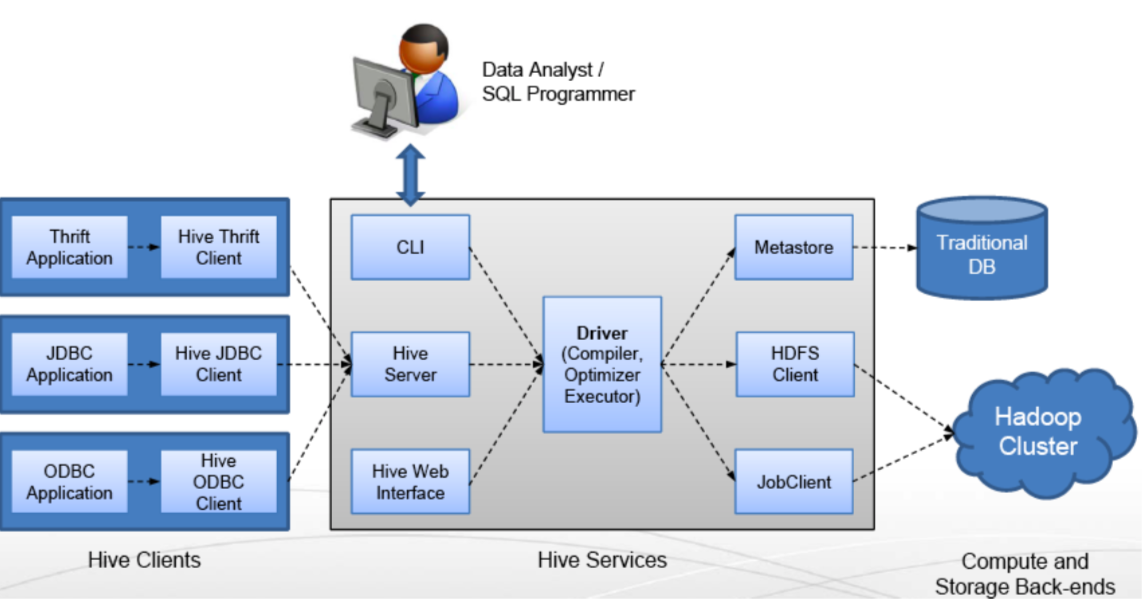
注意hive主要的组件包括:
- Shell:也就是CLI,允许用户像RDBMS一样交互查询
- Driver:session的handle、fetch和execute
- Compiler:针对hql的parse,plan和optimize
- Execution:基于stage的DAG图(mr,hdfs,metadata)
- Metastore:包括表定义、表的命名空间和partition信息等,可以存在mysql等关系型数据库里
Problem
mysql会报关于ssl访问的warning,但不影响操作?
在hive-site.xml里的mysql配置里声明useSSL=false,如下:
1 | <property> |
update和delete无法使用,报错信息【Attempt to do update or delete using transaction manager that does not support these operations.】?
要明白hive的文件存储格式主要有:
- textfile:默认格式,行存储,磁盘开销大,数据解析开销大,hive无法进行合并和拆分,压缩的text文件,load最快
- sequencefile:二进制,以<key,value>形式序列化,行存储,可分割压缩,与hadoop api中mapfile兼容,需要通过text来转化load
- rcfile:数据按行分块,每块列存储,读尽量涉及最少block,性能不如sequencefile,load最慢
- orc:数据按行分块,每块列存储,效率比rcfile高(推荐)
- 自定义格式
这四种,只有orc是支持update和delete操作的,其他都不可以。我之前stored as textfile,自然报错。
hive分bucket的时候mr jobs没动,如何处理?
我使用了tez替代hive-mr来作为hive的执行引擎,网上说这样可以提高3倍效率。
hive on tez如何配置?
apache官网下载tez
在hadoop/etc/hadoop/下创建tez-site.xml文件,加上配置:
1
2
3
4
5
6<configuration>
<property>
<name>tez.lib.uris</name>
<value>/user/tez/tez.tar.gz</value>
</property>
</configuration>把位于apache-tez-0.9.0-bin/share下的tez.tar.gz放在hdfs的/user/tez下
修改hadoop-env.sh追加下面配置
1
2
3TEZ_CONF_DIR=xxx/tez-site.xml
TEZ_JARS=xxx/apache-tez-0.9.0-bin
export HADOOP_CLASSPATH=${HADOOP_CLASSPATH}:${TEZ_CONF_DIR}:${TEZ_JARS}/*:${TEZ_JARS}/lib/*重启hadoop以及hive
hive里写set hive.execution.engine=tez; (可以直接配在hive-site.xml里,如果想恢复可以写set hive.execution.engine=mr;)
如何开启Hive CLI的debug模式?
hive –hiveconf hive.root.logger=INFO,console 启动hive,这样可以直接在cli里看到log内容